Claude Fable 5: The Model Too Dangerous to Ship — Until Now
Anthropic just shipped Claude Fable 5 — the first public model in a new Mythos tier above Opus. It found 271 zero-days in Firefox, tops every coding benchmark, and costs 2× Opus. Here's what actually matters.
Anthropic just shipped a brand-new model — and it's not another Opus. Claude Fable 5 is the first public model in a whole new tier called Mythos, sitting above the entire Opus line. The wild part: it was so capable that Anthropic held it back for two months, calling it too dangerous to release. Now it's free for every paid subscriber — but only through June 22.
Here's what actually matters.
Why it was locked up#
The reason for the two-month delay is security, and the numbers are genuinely unsettling. Using the Mythos preview, Anthropic's research turned up 271 zero-day vulnerabilities in Firefox — confirmed by Mozilla, already patched in Firefox 150, with real CVEs attached. Some of those bugs had been buried in the codebase for 15 to 20 years.
And Firefox was just the start:
- A 27-year-old flaw in OpenBSD, one of the most hardened systems on earth.
- A 16-year-old bug in FFmpeg, a library that quietly sits under half the internet's media stack.
- A Linux kernel exploit chain that hands an attacker root access.
- And, per Anthropic, thousands more across every major OS and browser.
The uncomfortable truth underneath this: the skill that finds vulnerabilities is the same skill that weaponizes them. That's why Fable 5 ships as Mythos with the safety rails switched on — when a prompt touches cybersecurity, biology, or chemistry, it's quietly handed off to the more conservative Claude Opus 4.8.
The numbers#
Start where it got dangerous. On ExploitBench — the cybersecurity benchmark — Fable 5 scores 78%, against Opus 4.8 at 40% and GPT-5.5 at 34%. Nearly double the field. That's the vulnerability-hunting skill, measured.
But it isn't only security. On SWE-Bench Pro, the benchmark for real-world software engineering, Fable 5 hits 80.3% — a 21-point lead over OpenAI's best. It tops Terminal-Bench at 88%, leads on spatial reasoning, and Anthropic says it can run agentic coding tasks for days with minimal human intervention. Across the official scorecard, it leads essentially every coding and security row. This isn't an incremental bump — it's a new tier.
The take#
The model is stunning. Two things give us pause.
First, the price. Fable 5 runs $10 per million input tokens and $50 per million output — double Opus 4.8. Even inside a subscription's free window, it burns your plan allowance roughly twice as fast. Anthropic's revenue run rate just hit $47 billion, so clearly someone's paying — the bet is that for serious agentic work, capability beats cost.
Second, a quiet line in the model card. Anthropic added invisible safeguards that can degrade Fable's performance on AI-research tasks — without telling you. Critics have called that "shockingly hostile in a paid product": a silent handicap you can't see and can't log. Worth knowing before you trust it with your own research workflow.
What's next#
Benchmarks are one thing. Real work is another. So in our next video, we're putting all three head-to-head — Fable 5, Opus 4.8, and GPT-5.5 — on real software engineering, security, and bug-fixing tasks. Which one actually finds the bugs? Which one ships the fix? It's going to be fun.
In the meantime, if you're choosing an agent platform to wrap around these models, that's a different decision — see OpenClaw vs Hermes Agent. And if "agentic coding" still sounds like jargon, start with AI agents in 100 seconds.
New tier. New price. New race. Stay tuned for the comparison.
Watch the full video
@thekernelcast on YouTube

OpenClaw vs Hermes Agent: Which Should You Pick?
OpenClaw and Hermes Agent are 2026's top personal-AI-assistant platforms — both well-funded, both NVIDIA partners, built on completely different stacks. We score them across five technical dimensions and call an honest verdict.
read the take→
AI Agent in 100 Seconds
AI agents explained in 100 seconds — from keyword-matching chatbots to autonomous, goal-completing systems. Same chat window, completely new engine.
read the take→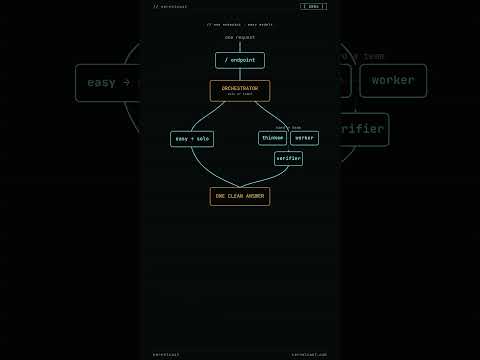
Sakana Fugu: AI Model That Matches Fable 5 on Key Benchmarks
Sakana's Fugu isn't a bigger model — it's a conductor. One endpoint that answers easy questions itself and hands hard ones to a team of specialists. Fugu Ultra hits 73.7 on SWE-Bench Pro, beating GPT-5.5, Opus, and Gemini — but it still rents its brains.
read the take→